
The research fields of Data Science, Statistics, and football performance analysis all converge on a key point: it is not possible to know with certainty what will happen in a match, but it is possible to estimate the probability of each scenario with a high degree of accuracy. And this distinction is not minor: it is precisely what has enabled the development of modern football analytics.
The central question: is football predictable?
Efforts to model and predict football are not new. As early as the 1950s and 1960s, the first statistical models applied to sports results emerged, notably the use of distributions such as Poisson to model goals in football, as in the work of Dixon & Coles (1997).
In the 1980s and 1990s, with the expansion of sports databases, these models became more complex and more predictive. The real breakthrough came in the last two decades with big data and real-time event tracking, which enabled much more granular performance analysis.
Today, football is analysed in a probabilistic and structural way, not only descriptively. Both professional clubs and betting markets use advanced models to estimate probabilities rather than exact outcomes. In this context, companies such as Opta Sports or StatsBomb have been fundamental in standardising event data and developing modern analytics.
In parallel, the use of metrics such as Expected Goals (xG) has made it possible to transform performance evaluation into a quantifiable measure of chance creation. At this point, the question is no longer whether football can be predicted exactly, but to what extent it can be reliably modelled within a probabilistic framework.

Prediction vs probability: a key distinction
At this stage, it is important to make a fundamental distinction. Understanding the difference between these two ideas is what separates a scientific approach to football from a purely intuitive one.
In football we do not predict what will happen, but how likely each scenario is. In statistics, probability is a way of measuring uncertainty based on available information, not a statement about what will actually occur.
- It is conditional, as it depends on input data
- It is dynamic, because it changes when the context changes
- It is not absolute, because residual uncertainty always exists
For example, when someone says: "I predict Real Madrid will beat Bayern Munich this weekend," they are using prediction as a binary statement (happens / does not happen). In a statistical approach, the correct way would be to speak in terms of a probability distribution:
Real Madrid might have a 55% chance of winning, a 25% chance of drawing, and a 20% chance of losing.
What science actually says about football predictions
Here lies the most interesting point. Football is a high-variance sport with very few decisive events. This means that a single goal can completely change the outcome of a match. Compared to other sports such as basketball, this makes outcomes much harder to predict, but performance easier to model.
If a team has a 70% probability of winning, losing 3 out of 10 times is not a model failure, but something entirely expected from a statistical standpoint. This principle is well documented in the literature on prediction and model calibration, such as in Dixon & Coles (1997).
Therefore, the takeaway is clear: do not judge a prediction by the result, but by whether the probabilities were well calibrated.
What can be measured vs what can be predicted in football
Here we try to understand the difference between what is measurable (descriptive) and what is predictable (probabilistic) in football.
Match-level outputs (what happens in a game)
Match-level outcomes describe what happens during the course of a game. We have different categories, but not all of them can be estimated with the same level of predictability.
Predicting shots, shots on target, corners, fouls and cards
These are events that occur frequently and also show structural stability. They are strongly linked to playing style, which means we have enough data to make reasonable average estimates, although not precise match-by-match predictions.
For example, we know that over a season a team performs:
- 10–20 shots, around 40% of which are on target
- 3–7 corners per match, with a tendency to increase in the second half
- 12–18 fouls, of which approximately 30% result in a card
Therefore, advanced models can estimate with reasonable certainty a team’s average number of shots, the probability of being over or under in corners, match tempo, possession, successful and failed passes, etc.
A good rule of thumb is the following: if an event repeats frequently, depends on playing style, and the effect of randomness is lower in aggregate, it is highly predictable.

Medium-frequency events: goals, extra time, etc.
Here we enter the realm of high-impact predictions. Imagine a team that scores between 1 and 3 goals in most of its matches. This introduces high variance, since outcomes depend heavily on isolated events.
Is it easier or harder to predict? The answer is that it can only be done probabilistically (not deterministically). Given an initial input, the result could be:
- 1-0
- 2-0
- 3-0
- 1-1
- 2-1
- ...
It is difficult because there are few high-impact events with high variability. A single well-executed shot can completely change the outcome. This is the domain of Expected Goals (xG) and Poisson distribution models.
Low-frequency events: match result
The final result is the sum of everything above and is extremely sensitive to small high-impact events. It can only be analysed in terms of aggregated probability.
Even the most advanced models are wrong in around 30–40% of cases when predicting the favourite. Football is a low-scoring sport, with high variability and a strong domino effect of rare events.
Player-based events: scorers, assists, etc.
Here the problem becomes even more complex. These events depend on multiple factors: minutes played, position, tactical role, teammates’ quality, individual form, and of course, randomness.
However, trends can still be identified in high-performing players. For example, a striker with a high volume of chances over a season is very likely to reach figures such as 20 goals. However, predicting this at individual match level is much more complex.
In short, there is strong dependence on team context, a highly uneven distribution (a few players concentrate most goals), and extremely discrete events.
Why these variables are difficult to predict accurately
The reality is the following:
Measuring football is relatively easy (shots, corners, xG, etc.). Predicting aggregates is reasonably possible. However, predicting results or individual events is inherently difficult.
Football is not unpredictable, but it is highly noisy at small scales. Part of its appeal lies precisely in that uncertainty: although it is not the most dynamic sport in terms of event volume, the impact of each event is enormous.
Factors that truly determine football predictions (causal variables)
Here we move closer to the perspective used in professional clubs. The goal is not so much to predict a specific result, but to understand which variables explain performance and how they translate into probabilities.
Which factors generate sustained advantages and how they translate into outcomes. We will go through them one by one:
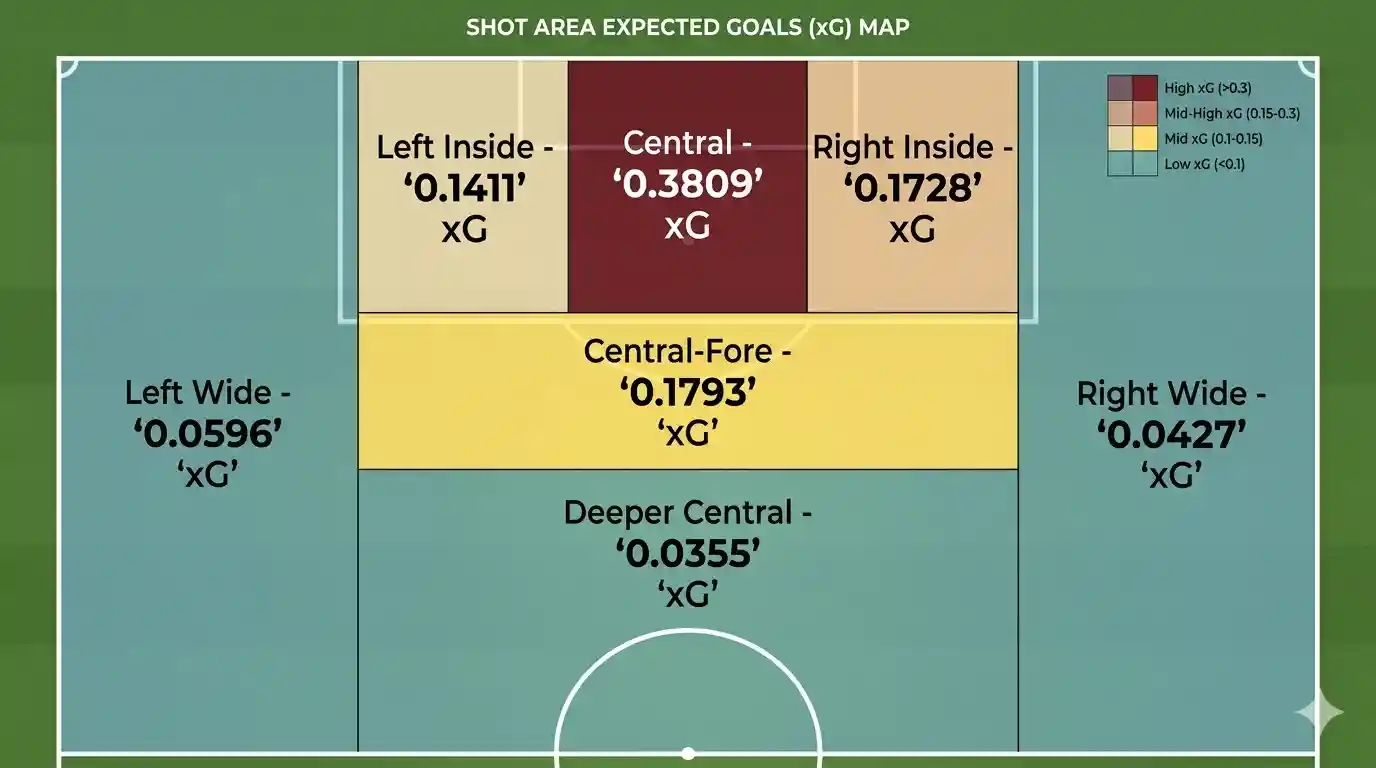
Expected Goals (xG) as a performance indicator
Imagine you are watching a match and a striker misses a shot in front of goal, with no goalkeeper and one metre from the line. You would probably think: "that was a clear goal." On the other hand, a shot from 40 metres barely creates expectation.
Expected Goals (xG) is the way models quantify that intuition. They analyse thousands of historical shots to estimate the probability of scoring in each situation.
- A penalty has an xG close to 0.76
- A long-range shot can have an xG of 0.01
Expected Goals (xG) is one of the central metrics in modern analysis. It allows performance to be evaluated beyond the result, measuring the quality of chances created.
In prediction, it helps estimate future goals, win probabilities, and identify when a team is performing above or below expectations.
Team strength systems and ratings
Team strength systems include Elo ratings, SPI-type models and Bayesian approaches.
Although they sound complex, they answer a simple question: which team is stronger right now?
Elo systems adjust ratings based on results and opponent quality. Beating a strong team is weighted more than beating a weak one.
SPI-type models incorporate more detailed statistics such as possession, shots, or attacking output to estimate a team’s true level.
Meanwhile, Bayesian models separate offensive and defensive performance to estimate how many goals a team is expected to score and concede, generating match outcome probabilities.
Tactical styles and team interactions
This includes aspects such as playing style (possession, transitions, low block), pressing intensity, or defensive line height.
Here, it is not only about team quality, but also how it matches up against the opponent. This is a key element in professional tactical analysis.
For example, a possession-dominant team against a low block usually generates fewer clear chances.
These variables help refine xG estimates, understand chance volume, and anticipate how a match will develop.
Player availability and squad depth
In this section, we estimate player availability and squad depth. This includes injuries, suspensions, accumulated minutes, squad depth, etc. These are key factors in estimating starting XI quality, substitutions, and fatigue resistance.
It is relevant because it allows direct adjustments to team strength, alters xG, and affects result variance. Teams with “broken” squads are less stable. Without squad depth, models break down.
Contextual factors (home advantage, fatigue, fixture congestion)
We now look at the “fine print” of football. This category includes all elements not directly related to talent, but which influence performance in a specific match.
Home advantage is the most classic factor: playing at home usually provides an extra boost, and statistics support this. Factors such as crowd support, familiarity with the environment, or even atmospheric pressure influence performance (Nevill et al., 2007).
Fatigue also matters: competing with rest is not the same as playing multiple matches in a short period. A fatigued team reduces intensity, makes more errors, and loses consistency. This is why load management is key within coaching staffs.
Finally, fixture congestion affects both physical condition and match preparation. It impacts not only fatigue but also the ability to train, make tactical adjustments, and maintain competitive level.
Advanced models include these factors as variables to correct predictions and better approximate real team performance.
Randomness and variance in football
This represents what is known in football as the chaos factor. Even with the best players and tactics, football remains one of the most unpredictable sports. Randomness and variance explain why the better team does not always win.
This includes, for example, refereeing errors: largely unpredictable and considered “noise” in the data. Over the long term they tend to balance out, but in a single match they can be decisive.
There are also isolated events: the low probability of a goalkeeper scoring a header in the 95th minute, a slip in a defensive action (such as the famous one by Steven Gerrard), or an early red card that changes the entire match.
Shot deviations, rebounds, or small random actions also fall into this category.

Conclusion: can football matches be predicted?
The short answer is that football matches cannot be predicted deterministically, but they can be modelled with a high level of probabilistic accuracy.
Throughout the analysis we have seen that football is a high-variance system, with few decisive events and a strong influence of randomness. This makes the final outcome inherently noisy and highly sensitive to small details.
However, not everything is uncertainty. There are structural patterns that allow probabilities to be estimated on a scientific basis. Variables such as Expected Goals (xG), team strength, tactical styles, player availability, or match context explain a large part of game behaviour.
This means that although we cannot know what will happen in a specific match, we can estimate with reasonable reliability which scenarios are more or less likely. And in that sense, prediction in football is not about getting a single result right, but about correctly calibrating probabilities over the long term.
In short, football is not predictable in the classical sense, but it is modelable. And that difference is the foundation of modern performance analysis and decision-making in professional football.
Learn more about tactical football analysis
Everything you have seen in this article is part of the daily work of the tactical football analyst. These are roles within clubs that interpret the game, analyse data, and generate useful insights for decision-making.
If you are interested in this approach, you can explore our Advanced Football Tactical Analyst Master. It is a programme designed for people who want to develop a professional understanding of the game and work in clubs, specialised media, or high-performance environments. No prior specific background is required.
If you want more information, you can contact us via WhatsApp and we will help you continue developing your football knowledge.




